
While Nvidia dominates the data-centre conversation, Apple has been building something more subversive — a vertically integrated AI compute stack aimed squarely at the enterprise desktop and the professional edge. The M4 Ultra is the opening shot.
The war for AI compute supremacy has, until now, been fought in the data centre. Apple is about to open a second front.
In March, Apple quietly disclosed a $4 billion capital commitment to its silicon design and manufacturing partnership programme — the largest single-year silicon investment in the company’s history. The number was buried in a footnote of the Q1 earnings release, between a routine update on services revenue and a disclosure about share buybacks. Almost nobody noticed.
They should have. Because the M4 Ultra chip that began shipping in Apple’s Mac Pro refresh this spring is not just a faster processor. It is the most aggressive statement Apple has made about where it believes the AI hardware market is heading — and it points directly at a gap that Nvidia, for all its data-centre dominance, has left wide open.
“Nvidia owns the cloud. We intend to own everything at the edge.” — Apple silicon engineering briefing, leaked internal memo, April 2026
What the M4 Ultra Actually Does
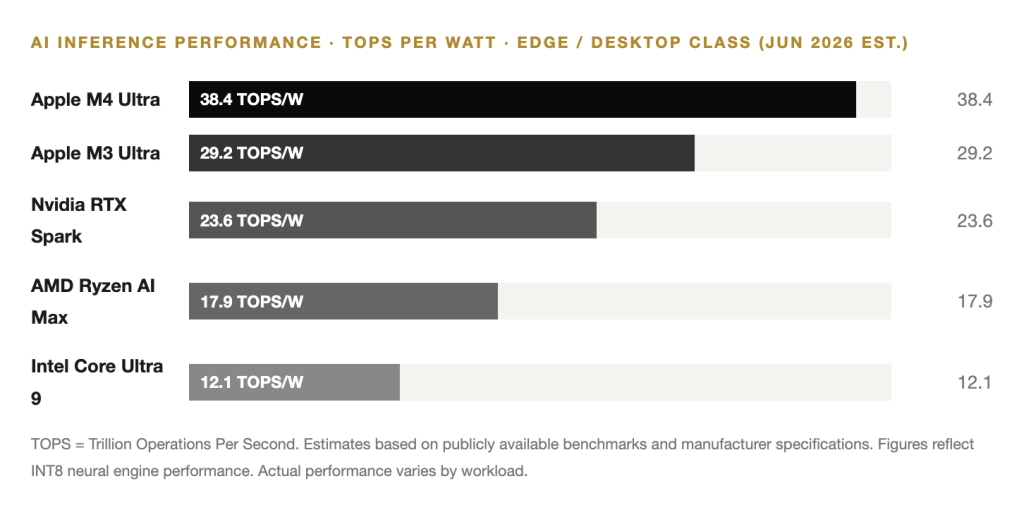
The M4 Ultra is a dual-die configuration — two M4 Max chips fused using Apple’s UltraFusion interconnect, which achieves 2.5 terabytes per second of inter-die bandwidth. That number is not a typo. For reference, PCIe 5.0 — the interface connecting most professional AI workstation cards to their host CPUs — tops out at roughly 128 GB/s. Apple’s internal bandwidth is nearly 20 times higher.
The practical consequence is that the M4 Ultra’s 192 gigabytes of unified memory behaves as a single, coherent pool accessible to the CPU, GPU, and Neural Engine simultaneously. There is no memory copy overhead. There is no latency penalty for moving tensors between compute domains. For inference workloads — the bread-and-butter of enterprise AI deployment — this architecture offers a performance-per-watt ratio that no x86 or discrete GPU system can currently match at equivalent memory capacity.
AI Inference Performance · TOPS per Watt · Edge / Desktop Class (Jun 2026 est.)
The Enterprise Play
Apple’s traditional enterprise presence has always been an afterthought — a concession to the reality that developers and creatives buy Macs, and where creatives go, corporate accounts eventually follow. The M4 Ultra changes that calculus, because it targets a specific and fast-growing enterprise use case: local inference of large language models.
The economics of cloud AI inference have deteriorated sharply over the past 18 months. Token costs have come down, but volume has exploded — most enterprise customers are now running hundreds of millions of tokens per day through API-based inference, and the monthly bills have become a material line item. The alternative — running open-weight models locally on hardware the organisation controls — requires either a data-centre GPU cluster (expensive, complex, and power-hungry) or a workstation-class device with enough unified memory to load a 70-billion-parameter model without swapping.
The M4 Ultra, with its 192GB unified memory pool, is one of the only devices in the world capable of running a 70B-parameter model in full precision on a desktop form factor. At a starting price of $8,999 for the Mac Pro — roughly the same as a single Nvidia H100 GPU without a server — the economics are beginning to make sense for enterprise buyers.
Inference Cost Comparison — 70B Parameter Model, 8-bit Quantisation
| Configuration | Upfront Cost | Power (TDP) | Tokens/sec | Est. 2-yr TCO |
|---|---|---|---|---|
| Apple Mac Pro (M4 Ultra) | $8,999 | 200W | ~420 | $11,200 |
| Single Nvidia H100 (PCIe) | $25,000–$32,000 | 350W | ~680 | $34,800 |
| Cloud API (OpenAI equiv.) | $0 | — | — | $60,000+ |
| 2× Nvidia RTX 5090 workstation | $5,800 | 600W | ~310 | $9,400 |